Everyone loves a good store catchment illustration.
Usually you will want to build a catchment from customer-side metrics, such as spend/visits per address/neighbourhood/suburb. However, these aren't always available - especially when a store is still in the planning stage!
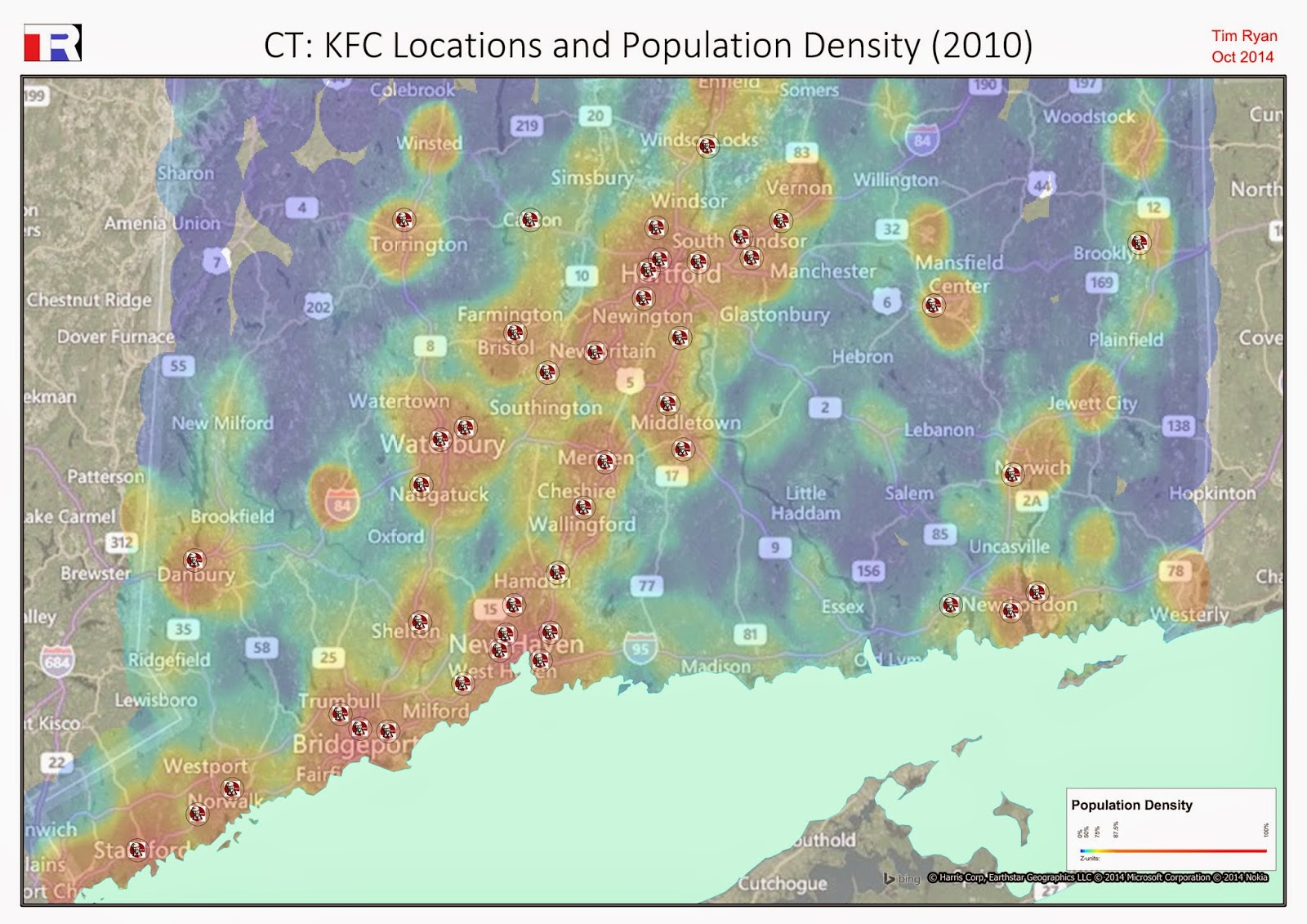
David Huff's 1963 retail patronage model - the Huff Model - has served as a useful catchment heuristic for over fifty years. The model predicts the likelihood of a person in a given location visiting a store, based on a) the 'attractiveness' of the store (relative to other stores) and b) the store's distance from that person (relative to other stores). Typically turnover - or proxies, like floor area or staff numbers - is used as the attractiveness score, with the distance measured as a straight line. The result is a patronage probability grid, like this:
 |
| 'Naive' patronage probability surfaces based on store turnover (Huff Model) |
Because the probability grid operates on straight-line distance, it ignores geographic constraints: rivers, mountains, ocean etc. The Huff Model therefore works best when accessibility is uniform - such as when streets are laid out in a perfect grid. Unfortunately this is rarely the case.
Enhancing the Huff
This can be done by:
- Creating a polygon-based grid
- Measuring the distance (or time, preferably) between each grid cell and each store by the road network
- The road network is, in most cases, the best representation of accessibility
- Assigning a probability score to each cell based on the time/distance vs attractiveness measurement.
- The score can be tweaked to represent the distance decay curve likely for the category - such as a flatter curve for a 'destination' location, or a steeper curve for a 'convenience' location.
- The probability scores can be calculated in almost any analytic software - even Excel.
- Mapping the scored cells.
- The map has two thematic layers. One shows the most attractive store for a given location. The second shows the intensity of the attraction; darker is more attractive.
Result
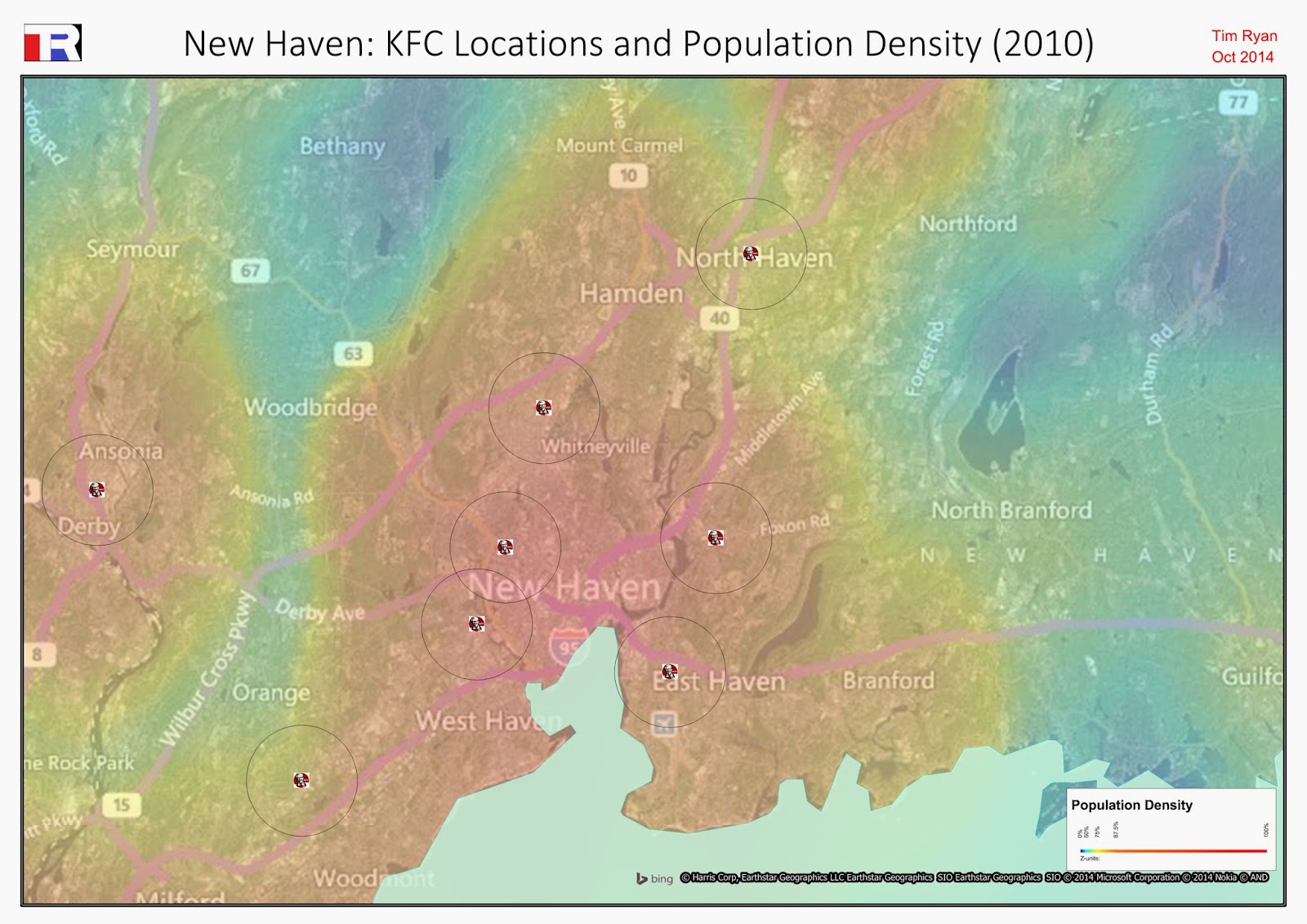
While the enhanced map (below, left) perhaps doesn't look as stylish, lacking the appealing contours of the naive Huff Model, it is significantly more accurate. For example, in the area below the text 'Sample 12' on the map, the patronage probability has decreased from 0.9 to 0.5. The enhanced road-based model recognises that the harbour creates an impassable barrier, and scores the area on its true store accessibility.

With a more accurate model, more accurate catchments can be generated. The above process also has the added benefit of retaining all store attractiveness scores within the cells. This means catchment overlap can also considered - important, since catchments are very rarely exclusive.
 |
| Drive-time enhanced patronage probability surfaces based on store turnover |






{kind=link}